Computational Framework for Real-Time Digital Twins
Introduction
The concept of Digital Twins (DT), pioneered by Grieves and Vickers (2016), has gained significant attention in various industries and academia. It marks a paradigm shift in digital transformation [see Grieves (2023) for a history of DT]. DT is a virtual representation of a physical system that undergoes continuous updates from real-time data, enabling simulation, analysis, and control. Despite the theoretical promise, real-time implementation of DTs remains challenging due to the high computational costs associated with forward model simulations. This article introduces a novel Physical-to-Digital-Digital-to-Physical (PDDP) framework that enhances the conventional DT approach by introducing a Digital-to-Digital (D2D) self-learning module.
The Standard PDP Data Flow
Successful implementation of DTs hinges on a bi-directional data exchange between the physical and digital entities. The standard Physical-to-Digital-to-Physical (PDP) data flow consists of two primary processes:
- Physical-to-Digital (P2D) process. Data from the Physical Twin (PT) is continuously fed into the DT, ensuring synchronization and an accurate representation of a physical system.
- Digital-to-Physical (D2P) process. The DT provides real-time control adjustments to the PT in response to environmental changes and operational objectives.
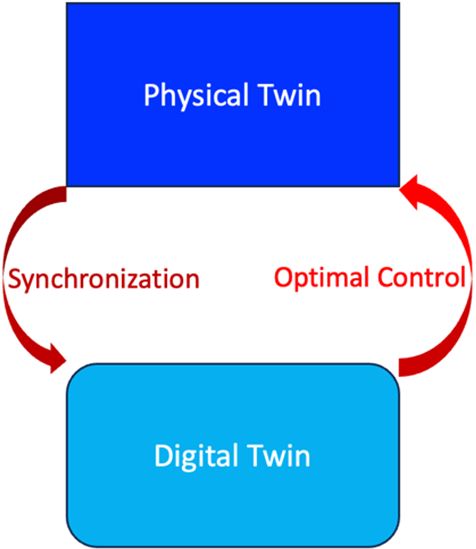
Figure 1. The standard PDP data flow for Digital Twins
Core Computational Challenges
Despite advances in computational hardware and numerical algorithms, the real-time execution of DTs remains a significant challenge, primarily due to their high computational demands. In particular, the DT (forward) model simulations are often highly time-consuming. Furthermore, many of the aforementioned critical tasks, such as optimization and control, require repetitive executions of the forward model simulations, further compounding the computational burden. The construction of a reduced-order model or a neural-network surrogate of the forward model may help alleviate this cost. However, such approaches rarely provide sufficient speedup to fully overcome the challenge.
Novel PDDP Framework
To address these challenges, we propose the PDDP computational framework, which enhances the traditional PDP model by incorporating a D2D module. This addition enables the DT to continuously refine its predictive capabilities and optimal control strategies in virtual time, independent of real-world data acquisition. See Fig. 2 for an illustration of the PDDP data flow.

Figure 2. The proposed PDDP data flow for Digital Twins
Key Components of the PDDP Framework
- Targeted Digital Twin (tDT) development
- The D2D module conducts repetitive simulations of the full DT to construct accurate dynamical models for the quantities of interest (QoIs). The tDT represents an ultra-fast model that can simulate and predict the QoIs directly without requiring full DT simulations.
- Used in conjunction with optimal control algorithms, the tDT model enables real-time D2P execution.
- Pre-learned optimal control strategies
- The tDT explores exhaustive “what-if” scenarios in virtual time.
- Optimal responses to various hypothetical situations are precomputed, enabling an instantaneous reaction to a real-world situation.
- This approach eliminates the need for computationally expensive real-time DT optimization and control.
Unique Features of the D2D Process
The D2D self-learning module operates continuously, refining the DT's predictive capabilities over time. Several key features distinguish this process:
- Extensive DT simulations in virtual time. Although this may seem counterintuitive due to computational costs, it forms the foundation of the PDDP framework. The full DT simulations occur independently of the PT, producing refined tDT models and pre-learned control strategies over time.
- Independence from real-world data. Unlike conventional methods that rely on real-time observational data, D2D self-learning operates using randomized hyperparameters embedded in the DT. This provides continuous model improvement without requiring direct input from the PT.
- Continuous model enhancement. Since D2D self-learning is perpetual, the fidelity and accuracy of the DT improve over time. By the time a real-world PT is deployed, the DT has already developed with highly optimized pre-learned control strategies, enabling real-time D2P execution without resorting to full DT simulations.
Motivational Example
A key inspiration of our PDDP framework is DeepMind's AlphaGo (see Fig. 3), an artificial intelligence engine designed for the game of Go (Silver, et al., 2017). With Go's immense computational complexity, AlphaGo mastered the game by first creating a game engine (a digital twin) and then playing a vast number of games against itself—a D2D process.

During this process, the DT (AlphaGo) analyzed the winning probability of every move in every games. This learning occurred entirely in virtual time and without human input (independence from real-world data). The more AlphaGo played against itself, the more refined its strategies became (continuous model enhancement). Eventually, this D2D learning enabled AlphaGo to respond in real-time when competing against human opponents.
Conclusion
The PDDP framework offers a promising approach to overcoming the computational barriers associated with real-time DT implementation. By incorporating a D2D module that enables continuous self-learning in virtual time, PDDP ensures that DTs can provide instantaneous and optimized responses to real-world scenarios. This novel approach holds the potential to revolutionize industries by facilitating more efficient, intelligent, and adaptive digital twin applications.
REFERENCES
Grieves, M. (2023) Digital Twins: Past, Present, and Future, in N. Crespi, A. Drobot, and R. Minerva, The Digital Twin, Springer, 97–121.
Grieves, M. and Vickers, J. (2016) Origin of the Digital Twin Concept, Florida Institute of Technology, 8: 3–20.
National Academy of Engineering and National Academies of Sciences (2024) Foundational Research Gaps and Future Directions for Digital Twins, The National Academies Press.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L., van den Driessche, G., Graepel, T., and Hassabis, D. (2017) Mastering the Game of Go without Human Knowledge, Nature, 550: 354–359.
参考文献列表
- Grieves, M. (2023) Digital Twins: Past, Present, and Future, in N. Crespi, A. Drobot, and R. Minerva, The Digital Twin, Springer, 97–121.
- Grieves, M. and Vickers, J. (2016) Origin of the Digital Twin Concept, Florida Institute of Technology, 8: 3–20.
- National Academy of Engineering and National Academies of Sciences (2024) Foundational Research Gaps and Future Directions for Digital Twins, The National Academies Press.
- Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L., van den Driessche, G., Graepel, T., and Hassabis, D. (2017) Mastering the Game of Go without Human Knowledge, Nature, 550: 354–359.